Query的使用
Spring官方文档:https://docs.spring.io/spring-data/elasticsearch/reference/elasticsearch/template.html#elasticsearch.operations.queries
Query是Springboot定义的接口,他的实现类如下:
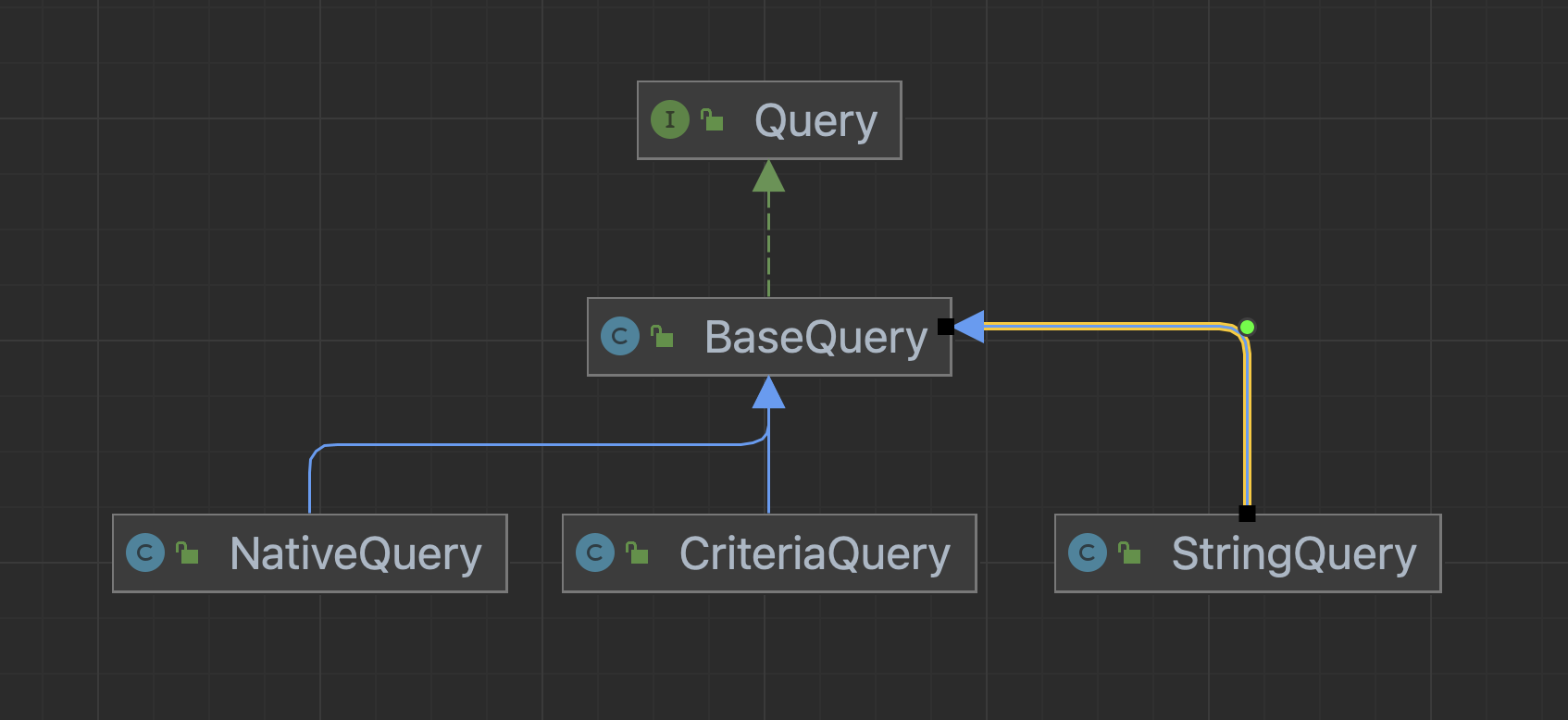
使用StringQuery
直接接收DSL语句,你可以编写语句,然后转换成字符串直接进行查询,前提是你对语法相当熟练。
举例1:
1
| 查询字段city为Cumminsville或者state=NY, 并且过滤出balance在25000至50000之间
|
如果使用REST API的调用方式,我们的请求体构造查询条件如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| {
"query": {
"bool": {
"should": [
{
"match": {
"state": "NY"
}
},
{
"match": {
"city": "Cumminsville"
}
}
],
"filter": {
"range": {
"balance": {
"ge": 25000,
"le": 50000
}
}
}
}
}
}
|
使用StringQuery我们可以直接传入json字符串,不需要包装最外层的query
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| @Test
void stringQueryTest() {
String source = """
{
"bool": {
"should": [ // should表示 or , must表示and
{
"match": {
"state": "NY" // 所查询的条件
}
},
{
"match": {
"city": "Cumminsville" // 所查询的条件
}
}
],
"filter": {
"range": { //范围查询
"balance": {
"gte": 25000, //大于等于
"lte": 50000 //小于等于
}
}
}
}
}
""";
StringQuery query = StringQuery.builder(source).build();
SearchHits<Balance> search = elasticsearchTemplate.search(query, Balance.class);
search.getSearchHits().forEach(balanceSearchHit -> {
System.out.println(balanceSearchHit.getContent());
});
}
|
CriteriaQuery使用
使用CriteriaQuery我们可以创建一个Criteria对象,通过链式调用的方法,来指定检索条件
1
2
| Criteria age = new Criteria("age")
.greaterThanEqual(18).lessThanEqual(40);
|
也可以通过and和or来继续指定检索条件
1
| Criteria miller = new Criteria("lastName").is("Miller").or("city").is("Cumminsville")
|
也可以嵌套子查询,子查询与父查询以and关联
1
2
3
4
5
| Criteria miller = new Criteria("lasename").is("Miller")
.subCriteria(
new Criteria().or("firstname").is("John")
.or("firstname").is("Jack")
);
|
测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| @Test
void criteriaTest() {
Criteria age = new Criteria("age").greaterThanEqual(18).lessThanEqual(40);
CriteriaQuery criteriaQuery = new CriteriaQuery(age);
SearchHits<Balance> search1 = elasticsearchTemplate.search(criteriaQuery, Balance.class);
search1.getSearchHits().forEach(balanceSearchHit -> {
System.out.println(balanceSearchHit.getContent().toString());
});
System.out.println("=============");
Criteria miller = new Criteria("lastname").is("Miller")
.subCriteria(
new Criteria().or("firstname").is("John")
.or("firstname").is("Jack")
);
CriteriaQuery query = new CriteriaQuery(miller);
SearchHits<Balance> search2 = elasticsearchTemplate.search(query, Balance.class);
search2.getSearchHits().forEach(balanceSearchHit -> {
System.out.println(balanceSearchHit.getContent().toString());
});
System.out.println("============");
Criteria criteria = new Criteria("lastname").is("Miller").or("city").is("Cumminsville");
CriteriaQuery multipleQuery = new CriteriaQuery(criteria);
SearchHits<Balance> search = elasticsearchTemplate.search(multipleQuery, Balance.class);
search.getSearchHits().forEach(hit -> {
System.out.println(hit.getContent());
});
}
|
NativeQuery使用
NativeQuery功能更强大,直接使用Lambda表达式,一路到底,支持聚合、匹配,可以实现复杂的检索查询及聚合查询、嵌套聚合查询。好处是可以直接通过表达式构造
还是以举例1做代码说明, 直接通过NativeQuery.builder()进行构建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| @Test
void simpleNativeQueryTest() {
var query = NativeQuery.builder()
.withQuery(m -> m.match(p -> p.field("state").query("NY")))
.withFilter(f -> f.range(r -> r.field("age").gte(JsonData.of(25))))
.withSort(s -> s.field(f -> f.field("balance").order(SortOrder.Desc)))
.build();
SearchHits<Balance> search = elasticsearchTemplate.search(query, Balance.class);
search.getSearchHits().forEach(hit -> {
System.out.println(hit.getContent());
});
}
|
使用native进行聚合查询以及嵌套的聚合查询
举例2:
1
2
3
| 1. 计算不同年龄员工的个数
2. 计算所有员工的平均薪资
3. 计算不同年龄段的平均薪资
|
同理,我们使用NativeQuery构造,并使用withAggregation构造聚合检索条件,(包含:terms、avg、sum等)
- 计算不同年龄员工的个数
withAggregation函数的第一个入参是自定义,指定本次聚合的名称。 size用来指定聚合后数据的长度,size(10)那就只取10组数据
1
2
3
4
5
6
7
8
|
var query = NativeQuery.builder()
.withAggregation("ageAgg", AggregationBuilders.terms(builder -> {
builder.field("age").size(10);
return builder;
})).build();
|
- 计算所有员工的平均薪资
使用avg函数就行
1
2
3
4
5
| var query = NativeQuery.builder()
.withAggregation("balanceAvg", AggregationBuilders.avg(builder -> {
builder.field("balance");
return builder;
})).build();
|
- 计算每个年龄的平均薪资
我们可以使用嵌套聚合的方式,先通过terms聚合不同年龄(名称为”ageAgg”), 然后再”ageAgg”中再次嵌套聚合avg,具体方式如下:
1
2
3
4
| var query = NativeQuery.builder()
.withAggregation("ageAgg", Aggregation.of(builder -> builder.terms(t -> t.field("age"))
.aggregations("balance_agg_01", AggregationBuilders.avg(t -> t.field("balance")))))
.build();
|
构建聚合条件时,可以使用Aggregation.of(), 也可以使用AggregationBuilders#(avg,sum,terms...)
如何从SearchHits中获取检索到的数据
在使用ElasticsearchTemplate#search时,返回的是一个org.springframework.data.elasticsearch.core.SearchHits对象
该对象中包含了SearchHit(检索命中的文档)、AggregationsContainer(聚合查询数据)等

我们在进行检索,构造检索条件时,如果要按照条件检索数据,我们用到了withQuery(),而使用聚合时,我们用到了withAggregation()。检索命中数据、聚合数据分别可以通过SearchHit#getAggregations和Search#getSearchHits方法来获取。分别来说
withQuery() - getSearchHits()
我们可以得到一个数组:List<SearchHit<T>>,对应到本文举例,那就是:
1
| List<SearchHit<Balance>> searchHits = result.getSearchHits();
|
我们可以看看SearchHit对象
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| public class SearchHit<T> {
@Nullable private final String index;
@Nullable private final String id;
private final float score;
private final List<Object> sortValues;
private final T content;
private final Map<String, List<String>> highlightFields = new LinkedHashMap<>();
private final Map<String, SearchHits<?>> innerHits = new LinkedHashMap<>();
@Nullable private final NestedMetaData nestedMetaData;
@Nullable private final String routing;
@Nullable private final Explanation explanation;
private final List<String> matchedQueries = new ArrayList<>();
}
|
因此,我们想要数据,直接遍历取出Content即可:
1
| List<Balance> docList = searchResult.getSearchHits().stream().map(SearchHit::getContent).toList();
|
withAggregation-getAggregations
我们调用getAggregations方法返回的是一个AggregationsContainer对象,而该类为接口,我们可以将它转换成他的实现类

1
| ElasticsearchAggregations aggregations = (ElasticsearchAggregations) search.getAggregations();
|
我们通过debug的方式来查看aggregations对象是怎么保存我们的聚合查询结果的。如下图所示:

可以看到,真实的对象确实是ElasticsearchAggregations,除此之外,aggregations是一个数组,存储了所有的聚合查询。
而每一个聚合都是一个ElasticsearchAggregation对象,由两个属性组成: name(也就是我们在构建检索对象时所定义的)、Aggregate所有聚合的信息
Aggregate: 我们根据debug的结果可以看出来,真实存储聚合结果的是**Buckets**,首先是聚合结果的数据类型,我们这里是计算每个年龄的薪资平均值,肯定有多个,所以_kind = Array,是一个数组,而_value则是我们想要的数据。
接下来就是获取到这些buckets
首先,我们定义了聚合的名称,而刚好Aggregations提供了一个方法,我们可以转换成一个以名称为key,ElasticsearchAggregation为对象的Map结构
1
2
3
4
5
| Map<String, ElasticsearchAggregation> aggregationMap = aggregations.aggregationsAsMap();
ElasticsearchAggregation ageAgg = aggregationMap.get("ageAgg");
ElasticsearchAggregation balanceAvg = aggregationMap.get("balanceAvg");
ElasticsearchAggregation ageAvg = aggregationMap.get("ageAvg");
ElasticsearchAggregation balanceAgeGroup = aggregationMap.get("balance_age_group_no_sort");
|
获取到所有聚合结果后,我们可以根据实际的聚合场景来进行取值, 比如:ageAgg和balanceAgeGroup,聚合查询结果的_kind肯定是数组,而balanceAvg和ageAvg,则_kind是Avg。
PS: 所有类型参照:co.elastic.clients.elasticsearch._types.aggregations.Aggregate.Kind
对于求和或者平均值,我们可以直接取到结果:
1
| double value = balanceAvg.aggregation().getAggregate().avg().value();
|
根据debug的数据结果,对于是数组结果的,我们想要获取到聚合结果,要先从ElasticsearchAggregation中取到Buckets,可以按照如下方式获取:
1
2
| Buckets<LongTermsBucket> buckets = ageAgg.aggregation().getAggregate().lterms().buckets();
Buckets<LongTermsBucket> buckets1 = balanceAgeGroup.aggregation().getAggregate().lterms().buckets();
|
这里.lterms()是因为聚合的数据类型为Long, 如果你聚合的数据类型是Double,用dterms(), 这个地方是和es的数据类型对应的
拿到buckets后,我们可以调用.array()方法将Buckets转换成数组,然后遍历拿到结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| buckets.array().forEach(bucket -> {
System.out.println("ageAgg, key = " + bucket.key() + ", value = " + bucket.docCount());
});
buckets1.array().forEach(bucket -> {
long l = bucket.docCount();
long age = bucket.key();
bucket.aggregations().forEach((k, v) -> {
System.out.println("age: " + age + ", count = " + l + ", key = " + k + ", value = " + v.avg().value());
});
});
|
网上使用NativeQuery的博客比较少,Spring官网也只是随便介绍了一下。有一些具体的用法还得慢慢摸索。