分布式理论
分布式架构,将服务模块部署到不同的机器上,来缓解系统压力。在同一台机器上,不会存在数据的一致性等问题。但是由于分布式中,服务部署在不同机器上,网络原因是不可抗因素。
CAP,一致性、可用性、分区容错性。必须要保证由于故障导致某些节点断掉以后,每个网络区域都能够对外提供服务,所以分区容错性是前提。而要保证高可用性,数据的一致性就得不到保证;要保证一致性,那么高可用性必然有所影响。
eureka和zookeeper可以作为分布式系统中的注册中心。注册中心负责服务的注册与查找,服务提供者会在注册中心注册自己的服务,消费者向注册中心订阅自己的服务,而注册中心就是一个服务列表。
两者比较:
eureka保证了CP,即可用性,在eureka中,每个节点都是平等的,当一个节点挂掉后,也不会影响正常工作,但是查询到的数据不一定是最新的。并且eureka有自我保护机制,当有85%的节点都没有正常工作时,会判定会注册中心网络故障。
zookeeper保证了AP,即一致性,在zookeeper中,节点有三种角色,leader、follower、observer,leader即为领导者,提供读和写的服务,负责投票的发起和决议,更新系统的状态;follower即跟随者,主要负责读服务,如果遇到写服务,则会将请求转发给leader,并且可以参加选举投票;observer和follower一样,但是不参加选举投票。如果leader挂掉,会重新投票选举出新的leader。并且在整个过程中,系统是不可用的。但是保证了数据的一致性。
一致性
如何保证一致性。有几种方案。
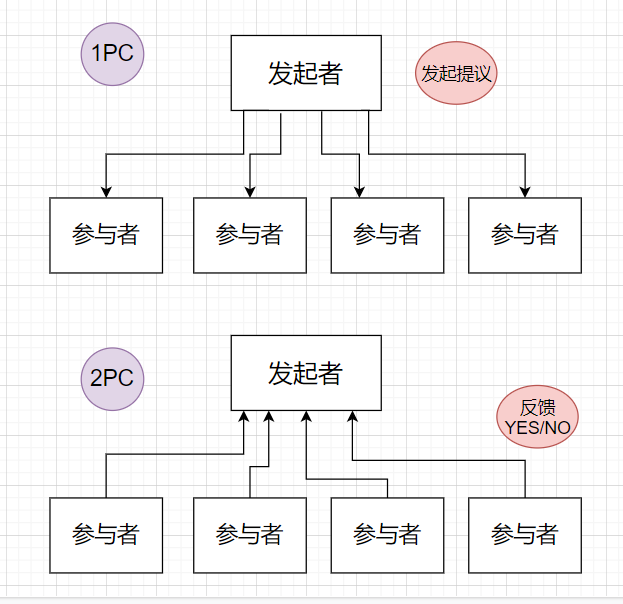
2PC
2PC,2 Phase Commit,2阶段提交。总共有两个阶段。
阶段一: 在执行一个分布式事务时,事务的发起者会向参与者发送一个prepare请求,参与者收到请求之后,会执行事务,但是不提交,执行后给发起者回复;
阶段二: 发起者会根据参与者的反馈来作出事务操作。如果所有参与者都没问题,则直接提交事务。如果某一参与者有异常等问题,则直接回滚。
2PC存在的问题:
1. 阻塞问题,在第一阶段的时候,参与者收到prepare请求之后,执行事务但是不提交,就会一直阻塞,这样会一直占用资源,并且如果这个时候发起者挂掉了,那么参与者将一直等待提交。
2. 发起者挂掉了,就直接无了。
3. 如果二阶段所有参与者都可以成功提交,那么发起者就会向参与者发送提交请求,此时发起者发了一半挂掉了,剩下的参与者将不会提交事务,这样就会导致数据不一致。
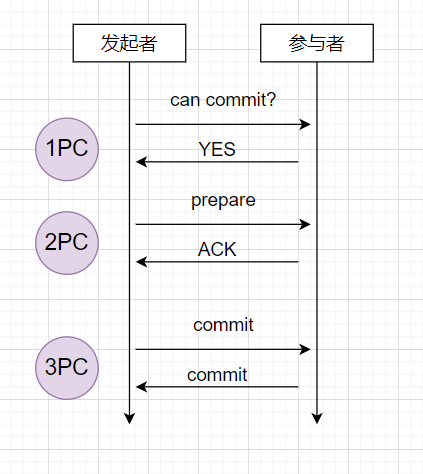
3PC
3PC,三阶段提交,与二节点提交不同的是,在第一阶段,发起者不会发送事务内容,会先确定参与者的状态。并且引入了超时机制。
一阶段(canCommit): 发起者(协调者)向所有参与者发送CanCommit请求,参与者收到后,判断自己是否可以执行事务,如果是YES,则让自己处于预备状态,在一定的时间内,如果没有做出反应,则为NO;
二阶段(preCommit): 发起者收到参与者的状态后,如果都可以,则向参与者发送prepare请求,让参与者先执行事务不提交,如果成功地执行了事务操作,则返回一个ACK给发起者;如果等待超时之后,发起者得不到响应,则判定为不成功,中断事务
三阶段(doCommit): 根据参与者的反馈,如果有参与者不能正常执行事务,则直接回滚;否则就发送提交请求。
3PC和2PC的比较:
3PC引入了超时机制,所以不会造成资源长期占用得不到释放。相比2PC来说减少了资源的阻塞问题。并且主要解决了单点故障问题。但是在数据的一致性上面还是得不到解决。在prepare阶段,如果此时有一个参与者可以执行事务,准备向发起者反馈,结果此时由于网络原因,超时了,由于发起者没有收到它的消息,所以会回滚事务,但是参与者自己提交了,这样就会出现数据的不一致。
paxos算法
paxos算法是通过消息传递,并且具有高度容错性的一致性算法。paxos算法中有三个角色,proposer提案者、Acceptor表决者、learner学习者。learner主要学习表决这批准的提案。paxos算法总共有两个阶段,分为:prepare、accept。
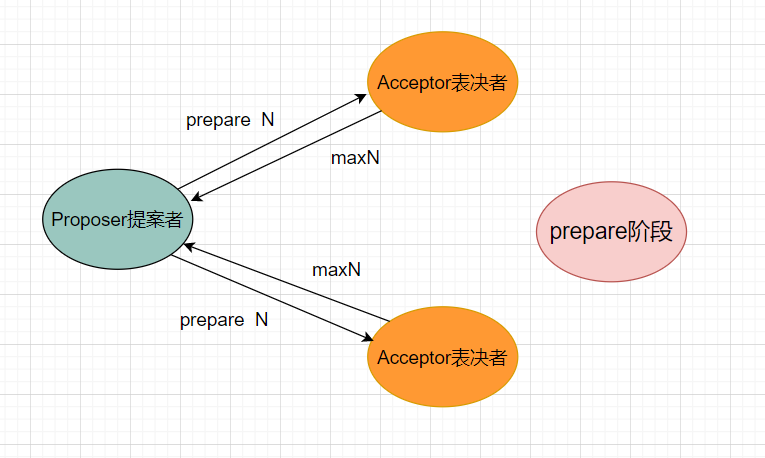
prepare阶段
提案者负责提案proposal,并且每一个提案都有一个编号N,这个编号具有唯一性、单调递增。该阶段,提案者会向表决者发送proposal编号N,表决者收到提案编号后,会与本地的编号maxN进行比较,如果N > maxN,则会接收accept提案,并且记录编号在本地,即maxN = N。并把当前最大提案编号maxN响应给提案者。
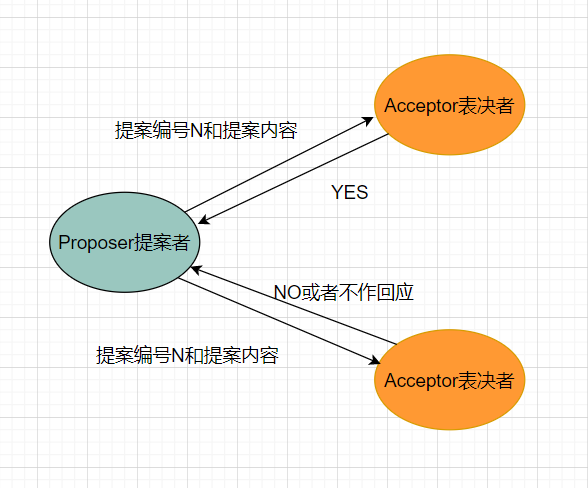
accept阶段
当提案者收到的批准数超过表决者的一半时,即有是超过一半的表决者批准了提案者的提案,提案者会将提案编号和内容一起发送给表决者。表决者收到后,会比较提案编号,如果本地最大编号小于等于收到的提案编号,则批准该提案,并执行提案内容,但是不提交。并将情况返回给提案者,不满足则返回NO或者不回应。
当提案者收到超过半数的表决者批准提案后(提案者会通过提案,此时三个节点有两个节点通过提案,则会进行提交),会向所有的表决者发送提交请求,向已经批准了的表决者发送提案编号就可以了,而那些没有批准的,则发送提案编号和提案内容。让它们无条件提交。
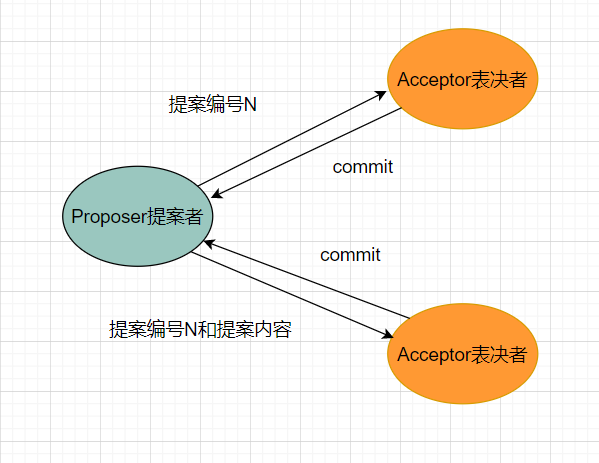
如果没有超过半数,则会重新进入prepare阶段,进行提案的表决。
paxos死循环
paxos会出现死循环问题。提案者P1提出M1,在prepare阶段被表决者批准。正准备进入二阶段;此时提案者P2又提出了M2,我们知道,提案编号是单调递增的,所以M2肯定是大于M1的,此时M2也在prepare阶段被批准,由于M2大于M1,所以会覆盖M1,而M1进入二阶段准备时,表决者发现提案编号小于本地编号,于是会拒绝,M1重新进入prepare阶段,又会覆盖M2,M2在二阶段又会不被批准,M2进入prepare阶段。。。这样就形成了死循环。
ZooKeeper
zookeeper并没有直接用paxos算法, 而是专门定制了一致性协议,叫做ZAB(Zookeeper Atomic-Broadcast)协议,原子广播协议。ZAB协议中有三个角色,Leader领导者、Follower跟随者、Observer观察者。
Leader: 集群中的领导者,唯一能处理写请求,并且可以发起投票;
Follower: 能够接收客户端请求,如果是读请求,则会自己进行处理;如果是写请求则会将请求转发给Leader,让Leader进行处理。可以参加选举投票。
Observer: 和Follower一样,但是没有投票权,也不能参加选举。
ZAB协议中有两种模式:消息广播模式 和 崩溃恢复。
消息广播模式
主要是同步数据,只有leader能处理写请求,leader会将写请求广播出去,如果有超过一般的follower同意更新,则会对follower和observer进行数据的同步和更新。所使用的原理和paxos算法一致,会有一个全局唯一、单调递增的事务ID: zxid,并且每台机器都会有一个自己的id:myid。
每个提案都是通过zxid来进行排序处理的。
崩溃恢复
如果运行过程中,集群中的follower和observer有节点挂掉了,因为leader还在正常运行,当挂掉的节点恢复后,leader可以维护。
但是leader挂掉了该怎么办?leader在整个zookeeper集群中只有一个,leader挂掉此时会暂停服务,进入LOOKING状态,然后进行leader的选举。
leader是如何选举的呢?
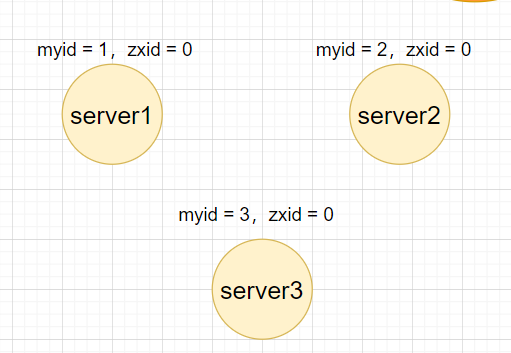
初始化选举
假设现在zookeeper集群中有三台服务器,他们的myid的值如图,因为初始化,所以它们的zxid 都为0。
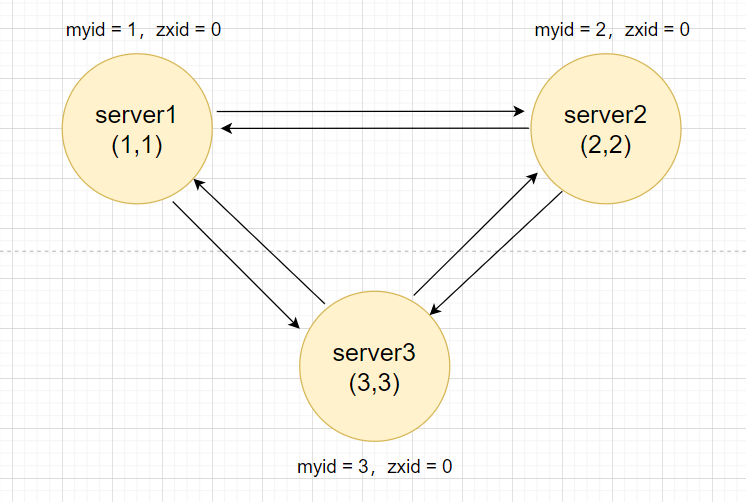
首先,每个服务器节点都会把票投给自己,然后将自己的投票广播出去,收到其他节点的投票之后,会与自己的作比较,会先比较zxid,如果zxid比自己大,则把自己的投票改成zxid大的那个,如果zxid一样大,则会比较myid,当发现获得票数超过一半后,就会变成leader。
给自己投票以后广播出去
当收到其他节点的投票之后,得到的投票情况如下
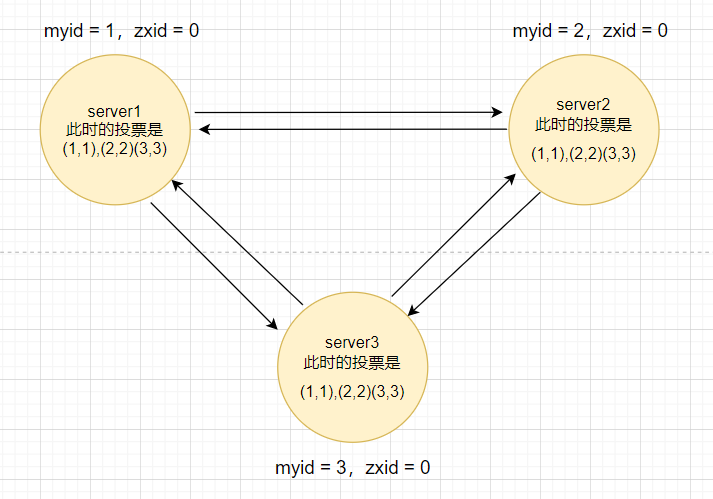
进行比较之后,server1和server2更改了自己的投票。如下
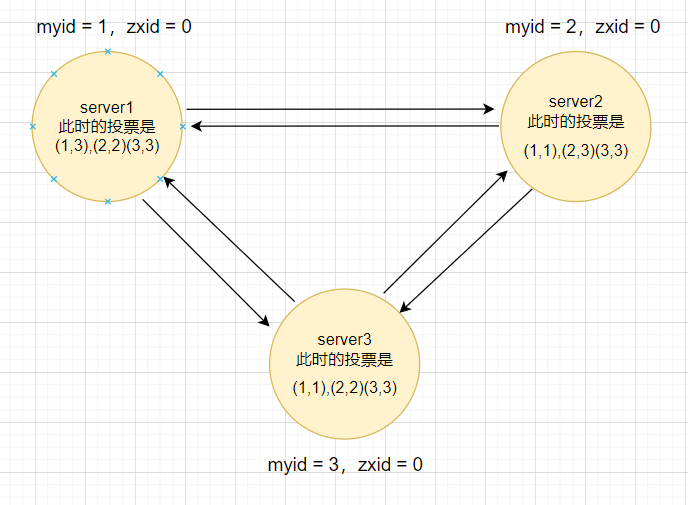
会再次进行广播,那么此时server3的票数已经超过一半,所以server3称为leader。
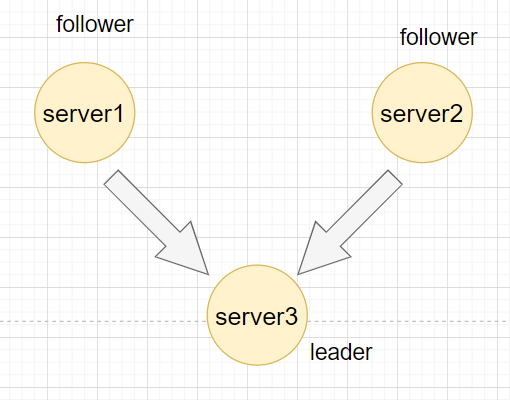
崩溃恢复
如果在运行过程中leader挂掉了怎么办? 系统会暂停服务,进入LOOKING状态,开始选举leader。ZAB是如何保证选举新leader后,数据的一致性的呢?
ZAB可以确保已经被leader提交的数据最终能被所有节点提交
假设server3正在向server1和server2发送提案,server1成功收到提案,而server2还没收到提案server3就挂掉了,此时暂停服务,进行选举,很明显,server1的zxid肯定大于server2,所以server1肯定是新的leader。这样就确保了leader提交的数据不会丢失,当server3重启,就会称为follower,server1通过广播方式将原先的提案发送给follower。
ZAB可以跳过被丢弃的提案
假设还是server3是leader,server3通过了提案P1,并且发送给server1和server2要提交的请求,但是此时server3挂掉了,经过选举之后,有一个成为leader,此时server3恢复,server3想要执行提案P1,但是此时的leader却没有这个提案,为了保证数据的一致性,这个提案会被丢弃。
zookeeper的功能挺强大的,有一个watcher机制,事件监听器,zookeeper的数据结构是一个个znode节点,znode节点包含了事务id,节点id,创建时间等等,可以通过监听器对node节点进行监听,实现选举、分布式锁等。