前述
redis作为当下十分热门的数据库缓存中间件,在很多项目中都有使用到。并且redis的性能也十分强大,可以缓解关系型数据库的IO压力。与Memcached相比,redis支持多种数据结构,并且redis可以周期性的将更新后的数据写入到磁盘中,即可以做持久化的操作。本文主要谈谈redis常见的五大数据结构,并且可以应用到哪些场景。
redis的五大数据结构有: string、list、set、hash、zset
1. String
string类型的数据大家应该很熟悉,在java中,String是字符串,在redis中,也是一样的,是redis中最基本的数据结构。redis是一款基于key-value键值对的开源框架。string类型即一个key对应一个value。并且value的最大容量是512M。并且string类型是二进制安全的,所以我们可以使用string类型来存储二进制文件或者序列化后的对象。
1.1 string常用命令
set 命令。通过set命令可以在redis中添加键值对。如果我要添加一个key-value是”k1”-“v1” 即可用如下操作。set k1 v1
可以添加键值对,那么就可以通过key来获取对应的value。使用get命令即可获取到与key对应的value
get k1
incr
如果想知道我们的key的长度,可以使用命令 strlen key 来获取。
除此之外,应用比较多得有一个指令。就是setnx,在高并发的情况下,我们通常需要添加分布式锁,而redis即可作为分布式锁,我们可以添加某一个键值对,为了防止某一线程抢占到该锁,在运行业务中途发生宕机等异常,锁得不到释放,导致其他线程也拿不到锁,我们可以为key设置上过期时间,而redis是单线程的,我们每一条指令都是一个原子性操作。所以使用setnx添加一个不存在的键值对,并设置过期时间。这样可以保证原子操作。当然,仅仅靠这个保证不了多线程访问锁的问题。这里不是讨论的重点。
string中还有很多其他的命令,如mset 可以设置多个键值对,mget可以通过多个key获得对应的value。等等,不过多赘述。
1.2 string数据结构
string的数据结构为简单动态字符串,即可以实现自动扩容。与java中的string不一样,redis中的字符串是可以修改的。类似于java中的ArrayList。 最大空间为512M,当字符串的大小小于1M时,会进行加倍扩容。而当字符串大小大于1M时,则每次会增加1M的空间。
1.3 应用场景
我们知道string有一个让key对应的value+1的命令,即incr。因此,我们可以使用string的这一特性来做评论的点赞,和商品的喜欢数。除此之外,例如有一个在线教育的网站,在网页的首页我们会显示一些热门老师即热门课程,我们可以使用string类型来存放这些数据。
2. list
list即一个key可以对应多个value。并且可以按照插入的顺序排序。我们可以从头部插入,也可以从尾部插入。由此可以得出结论,list其实是一个双向链表。对两端的操作性能会比较高。
2.1 常用命令
我们可以对一个key插入多个值,并且可以从左右两边插入,使用lpush/ rpush,从左/右边插入值。
lpop/rpop 即从左/右边弹出一个值,弹出的意思是弹出即不存在与key中,并且当key中没有value后,这个key就会被删除。
rpoplpush 看这个指令应该就可以看出是从右边弹出一个值加入到左边。
还有很多指令,这里就不过多赘述。
2.2 数据结构
前面说道,list其实是一个双向链表,但是其实和我们在数据结构或者java中所熟知的链表是有点区别的。在数据结构中,对于一个双向链表,我们是由一个一个节点所构成的,一个节点分为三部分,指向前驱结点的指针、存放数据的空间、指向后继节点的指针。而redis中的list所采用的数据结构可以叫做快速链表。ziplist,是一块连续的内存空间,当我们数据量比较少的时候,此时的数据结构是ziplist,而当数据量变大,很多个ziplist就形成一个双向链表,双向链表的每一个节点都是一个ziplist。
即,redis中的list,将双向链表与ziplist相结合。这样不仅满足了插入和删除的性能,并且不会浪费太多空间。因为,我们只有每个ziplist的首尾才需要指针。这样可以节约因为指针造成的空间浪费。
2.3 应用场景
我们可以利用list的两端插入删除的特性,来作为公众号文章的推送等。我们都会在微信中关注一些公众号,公众号可以通过list为我们推送最新的文章。
3. set
set和list一样可以支持 一个key对应多个value。但是set可以自动排重,其实与jdk中的还是挺像的。redis中set也是一个hash表。所以查找的速度也是非常快的。set也是无序的。
3.1 常用命令
sadd 用来添加元素到key中,smembers 取出key中的所有元素
sismembers 可以来判断集合中是否存在这个value,如果存在则返回1, 反之返回0。
spop 取出元素,与list不同的是,由于set是无序的,所以取出的元素是随机的。
sinter、sunion、sdiff 分别是两个集合的交集、并集、差集。 (差集: sdiff k1 k2, 则返回的是k1有,但是k2没有的。)
3.2 数据结构
set的数据机构是dict字典,dict使用哈希表实现的。redis中是通过一个dict字典来保存所有键值对的。因此,set的数据结构和jdk中的类似,底层实现用的是hashmap中的。
3.3 应用场景
在交集或者差集等场景下我们可以使用,比如微信朋友圈的点赞,只有相同好友才能看到。又比如通过交集,来获得微博的共同关注。利用set的无序特性,可以用来做微信的抽奖小程序。等等
4. hash
hash相比都熟悉,redis中的hash结构与java中的类似,通过一个key可以存储多个k-v键值对。例如我们可以用用户id作为key, 而value我们可以采用k-v键值对的形式,如 姓名:jack、年龄:12。
4.1 常用命令
其实和前面的都差不多,hash的命令都是以h开头。hset用来添加键值对,hget
4.2 数据结构
hash类型主要对应的是两种数据结构:一种是前面提到的ziplist,另一种则是hash表(hashtable)。当数据较少的时候,是ziplist,当数据量增大的时候,则使用hashtable。
4.3 应用场景
我们会在网上添加自己喜欢的商品到购物车,然后最后一起付款,那么,我们可以将用户的id作为key,value可以以键值对的方式,存放每个商品的数量及价格,通过hmget可以获取所有的商品。最后得到总价。 另外,还可以作为系统中对象的存储。在电商系统中,可以存放商品的信息。
5. zset
zset,即sorted set。即是可以排序的set,并且不允许元素的重复。zset是给每个元素加了一个score,这个评分可以作为排序。从而来获得每个元素的次序。
5.1 常用命令
zadd
zcount
等等。
5.2 数据结构
zset底层使用了两个数据结构:
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
跳跃表
1、简介
有序集合在生活中比较常见,例如根据成绩对学生排名,根据得分对玩家排名等。对于有序集合的底层实现,可以用数组、平衡树、链表等。数组不便元素的插入、删除;平衡树或红黑树虽然效率高但结构复杂;链表查询需要遍历所有效率低。Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
2、实例
对比有序链表和跳跃表,从链表中查询出51
(1) 有序链表

要查找值为51的元素,需要从第一个元素开始依次查找、比较才能找到。共需要6次比较。
(2) 跳跃表
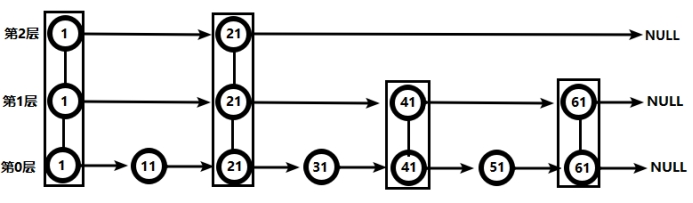
从第2层开始,1节点比51节点小,向后比较。
21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下
在第0层,51节点为要查找的节点,节点被找到,共查找4次。
从此可以看出跳跃表比有序链表效率要高
5.3 使用场景
根据分数这一特点,不难看出,其实我们在直播打赏榜,微博热搜等排行榜中都可以使用。
6.bitmap
除了常见的五种数据类型,其实redis中还有三种数据类型,即bitmap、hyperloglog、geospatial。这里只说明bitmap。
bitmap,翻译过来就是位图,即其存储的是连续的二进制数字,也就是0和1,我们只需要一个bit,即位来表示某一事物的状态。而key就是这个事物。这种数据结构可以节约很大部分的空间,因为,我们可以用1bit来表示一个事物的状态。
bitmap 常用的指令有 setbit key offset 0/1 返回的是key中偏移量的值(即0或者1)。
getbit key offset 查询key中该偏移量是否被访问过
我们可以使用bitmap来存储用户的状态,用户的行为分析,可以把用户喜爱的东西记录下来,即设置为1。 另外我们可以以时间为key 用户的id为offset, 来记录活跃用户。等等。
另外,bitmap有一个应用很重要,那就是布隆过滤器。
在redis中,我们会遇到缓存穿透的问题。缓存穿透是在一定时间内,有大量的请求来访问一个不存在的key,导致redis缓存不起作用,大量请求到达数据库,导致数据库崩溃。 我们则可以使用布隆过滤器先对请求进行拦截和筛选。
布隆过滤器,通过hash运算和一个bitmap。我们可以预先记录海量数据,当请求发送过来时,布隆过滤器会对用户传过来的key进行hash运算,并在bitmap上找到对应的下标。并查询出是否存在(判断存不存在,可以根据该下标对应的值是0还是1),当该key在bitmap中存在时,才可以访问redis,或者则直接返回。
因此,布隆过滤器可以很好的预防redis缓存穿透的问题,也是bitmap的应用。